IoT Project: Garden Monitor Prelude →
How can you grow a better crop without knowing your plant’s environment?
Specific to a plant’s enviornment are temperature and humidity. Keeping these metrics within a specific range, allows for optimal nutrient absorption.
Given the importance of these metrics, I reluctantly started out growing plants using a manual temperature humidity monitor. Thus, I only knew if the greenhouse is within the desired metric range during small windows of time throughout the day – when I physically check them.
What happens at night? When the lights turn on? Turn off? Unless you’re physically present to read the metrics during this time, who knows what the humidity and temperature is.
My plan was to develop a continuous monitoring solution with metrics pushed to a database.
The Plan
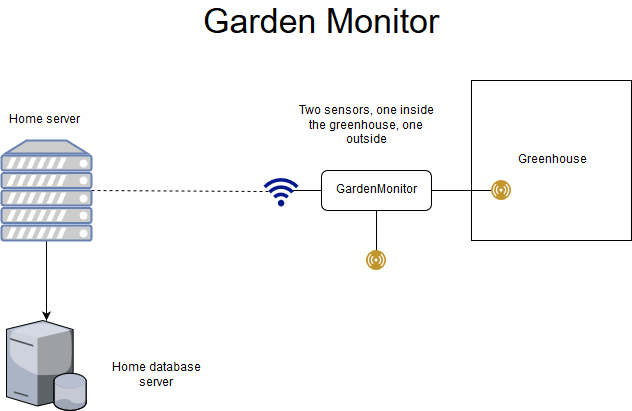
Using a few cheap parts, we can create a continuous monitoring system to allow us to capture data about the environment. Then, we can graph the data points and look for trends.
For my first prototype, I used a similar setup outlined below, except I had an Arduino Uno read the sensor data, and the Rasberry Pi was used to transmit data.
For the second prototype, I’ll have a temperature/humidity sensor within the greenhouse, and outside the greenhouse. This way, we can compare both the ambient and internal temperature/humidity metrics.
Below is the list of items I used for the initial prototype:
- 1x Rasberry Pi B+
- 2x DHT 22 Temperature/Humidity sensors
- Wires and resistors
- Old laptop to act as local server
An older Rasberry Pi will work, however I chose the B+ because of the integrated WiFi and Bluetooth chip. For older Rasberry Pi’s, you would either need a USB WiFi card, or use a physical Ethernet connection.
Home Server
For the server, I have an old laptop running Linux, with a Postgres instance running, and our server (simple Node.js CRUD application).
More optimally, I’d choose a hosting provider such as Digital Ocean, Linode, or AWS for the server.
Home Database
I have experience with Microsoft’s SQL server, and MySQL, but I wanted to try out PostgreSQL. I’ve heard great things from other developers, plus after version 9.2, PostgreSQL now natively supports JSON column type (This means we can now create indices with JSON data type).
For our purposes, a relational database makes the most sense, as opposed to a document store such as MongoDB. At the time of writing this, NoSQL is the current fad of the hour.
Safeguards
There are some fun features I want to try adding to the project, even if it would be overkill for our current requirements.
One such feature would be a caching system made on the Rasberry Pi. Essentially, if the HTTP server request fails, I want each of those requests cached until connection to the server is restored. After connection is restored, a sort of “back-fill” of previous data would be sent to the server.
This way, if the server goes down, we won’t have a gap in our sensor data.
A second feature is an automated backup system, where the database server will push backups to a remote server or backup service.
Conclusion
Now that we have a basic overview of the system, we can start defining more concrete plans with some Entity-Relation Diagrams, define the REST endpoints, and choose a language for our server found on the next post here